The Unexpected Showdown: Chess Masters vs. LLMs – Insights into Instruct Models
2024-11-16
Author: Emma
When we think about playing chess, we usually picture chess grandmasters grappling over a board, calculating moves and strategies. But what happens when we introduce large language models (LLMs) into the mix? At first, this concept might seem ludicrous; after all, LLMs are primarily trained on a plethora of texts and don’t inherently grasp the fundamentals of chess— such as board states or the roles of pieces like rooks and knights. However, recent experiments paint an intriguing picture.
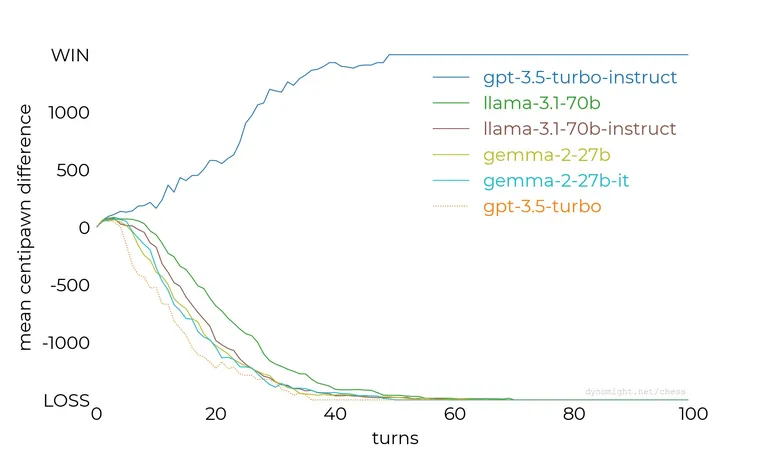
In a fascinating blog post by Dynomight, a showdown was staged between the advanced Stockfish chess AI and various LLMs, including a smaller Llama model and the more sophisticated GPT-3.5. While most of the results aligned with expectations—the LLMs struggled against a powerhouse like Stockfish—one standout did emerge: the gpt-3.5-turbo-instruct model performed surprisingly well, managing to challenge Stockfish even at its lower settings.
Each model faced an identical task: to embody a chess grandmaster, utilize standard chess notation, and select their next move. This highlighted a significant disparity, particularly between the instruct model and its counterparts, warranting a deeper examination. OpenAI characterizes the instruct model as an 'InstructGPT 3.5 class model.' This model leverages an extensive dataset combined with human feedback to enhance its effectiveness.
The magic behind the instruct models lies in their fine-tuning. Unlike standard LLMs, which may falter with instruction-based queries, instruct models have been meticulously designed to excel in such contexts. A noteworthy discussion on Hacker News from last year probed the differences between Turbo and Instruct versions of GPT-3.5, using chess as a pivotal reference point. ChatGPT, a close relative of InstructGPT, employs Reinforcement Learning from Human Feedback (RLHF), collating insights primarily from its user interactions.
Despite OpenAI's assurances that neither InstructGPT nor ChatGPT guarantees consistent accuracy, their performance in the domain of chess suggests they can occasionally hold their own. This could provoke interest among both chess enthusiasts and tech aficionados, showcasing how AI continues to evolve and surprise us in unexpected domains.
In conclusion, the chessboard isn't just a battlefield for traditional masters anymore. With advancements in AI and LLMs, we may witness a new era of chess competitions that meld human intuition with artificial intelligence’s analytical prowess. The question remains: Are we ready for this blend of strategy and technology? Be sure to stay tuned, as the realm of LLMs continues to unfold—there's much more than meets the eye!








 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)