Yeo Kheng Meng's Hilarious Hack: Running Llama 2 on a Vintage Intel 486!
2025-04-21
Author: Siti
The Retro Rocket Takes Off!
In a bold and amusing twist on the large language model craze, developer Yeo Kheng Meng has taken on the challenge of running the Llama 2 model completely locally—on old-school laptops powered by MS-DOS!
"Have you ever imagined running a large language model on a vintage PC? Now it’s a reality!" Meng poses provocatively. He recalls two years ago when he released a DOS client for OpenAI’s ChatGPT, sparking a wave of similar projects among retrocomputing fanatics. The challenge? Most of these efforts relied heavily on remote services. But Meng wondered if it was possible to keep things local.
Debunking the High-End Computer Myth
Traditionally, running large language models (LLMs) was deemed a task for only high-performance machines, loaded with powerful GPUs and copious amounts of VRAM. However, Meng's initiative flouts that conventional wisdom. By distilling models to their essence, he proves that even the most resource-constrained systems can handle basic LLM functionalities.
The Secret Sauce: Karpathy’s llama2.c
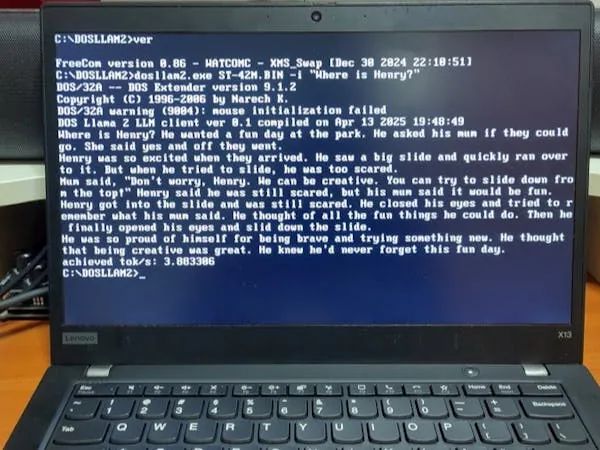
Meng’s secret weapon? The llama2.c inference engine created by Andrej Karpathy, designed for Meta’s freely-available Llama 2 model. Karpathy’s engine has been tailored to run on modest systems by focusing on smaller models trained on the TinyStories dataset, allowing some level of functionality where performance was once an illusion.
Getting It Running: A Technical Triumph
Choosing Open Watcom 2 as a compiler and DOS/32A as a DOS extender, Meng tailored the code to fit the quirks of vintage hardware. His labor of love means that while running these slimmed-down LLMs on older systems is possible, brace yourself for some patience! For instance, testing on an Intel 486 machine yielded a humble output of 2.08 tokens per second with the smallest model. Upgrading to a Toshiba Satellite with a Pentium MMX 200 saw that figure rise to a more respectable 15.32 tokens per second.
A Speedy Comparison to Modern Machines
In stark contrast, a modern desktop equipped with an AMD Ryzen 5 7600 effortlessly pulverizes these numbers, spewing out an astonishing 927.27 tokens per second with the same 260k parameter model. When utilizing a state-of-the-art inference engine, the potential speeds are even more mind-blowing, especially with the advantages of powerful GPUs!
Join the Retro Revolution!
Yeo Kheng Meng’s quirky project is not just about tech nostalgia—it's a playful rebellion against the notion that cutting-edge AI can only thrive on expensive hardware. By harnessing the charm of vintage computing, he invites enthusiasts to rethink what’s possible in the realm of artificial intelligence. Who knew nostalgia could run this deep, all the while spitting out basic language constructs?
 Brasil (PT)
Brasil (PT)
 Canada (EN)
Canada (EN)
 Chile (ES)
Chile (ES)
 Česko (CS)
Česko (CS)
 대한민국 (KO)
대한민국 (KO)
 España (ES)
España (ES)
 France (FR)
France (FR)
 Hong Kong (EN)
Hong Kong (EN)
 Italia (IT)
Italia (IT)
 日本 (JA)
日本 (JA)
 Magyarország (HU)
Magyarország (HU)
 Norge (NO)
Norge (NO)
 Polska (PL)
Polska (PL)
 Schweiz (DE)
Schweiz (DE)
 Singapore (EN)
Singapore (EN)
 Sverige (SV)
Sverige (SV)
 Suomi (FI)
Suomi (FI)
 Türkiye (TR)
Türkiye (TR)
 الإمارات العربية المتحدة (AR)
الإمارات العربية المتحدة (AR)